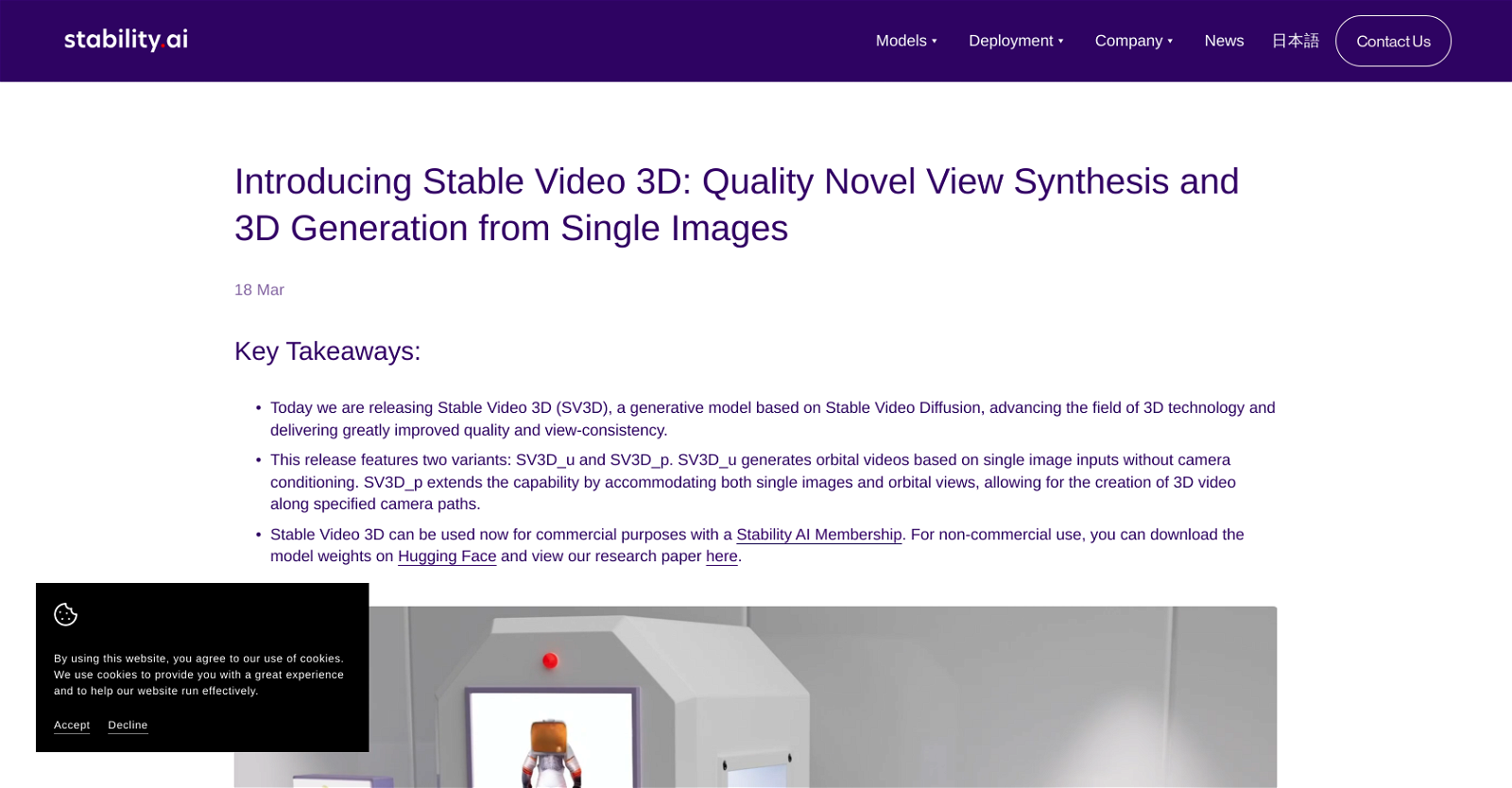
Stable Video 3D
Advancing 3D technology with quality novel view synthesis from single images.
About Stable Video 3D
Sponsored Ads

It seeks to
inspire and motivate individuals